正在加载今日诗词....
📌 Powered by Obsidian Digital Garden and Vercel
载入天数...载入时分秒... 总访问量次 🎉
载入天数...载入时分秒... 总访问量次 🎉
diffusion 是如何运作的
给一个带有噪声的图像,作为 Denoise 网络的输入,输出是减少了一些噪声的图像……依次经过 Denosie,经过有限次去噪过程,得到最后输入的图像。每一步都有一个编号,第一步是 1000,最后一步是 1。这个过程称为 Reverse Process(逆向过程)
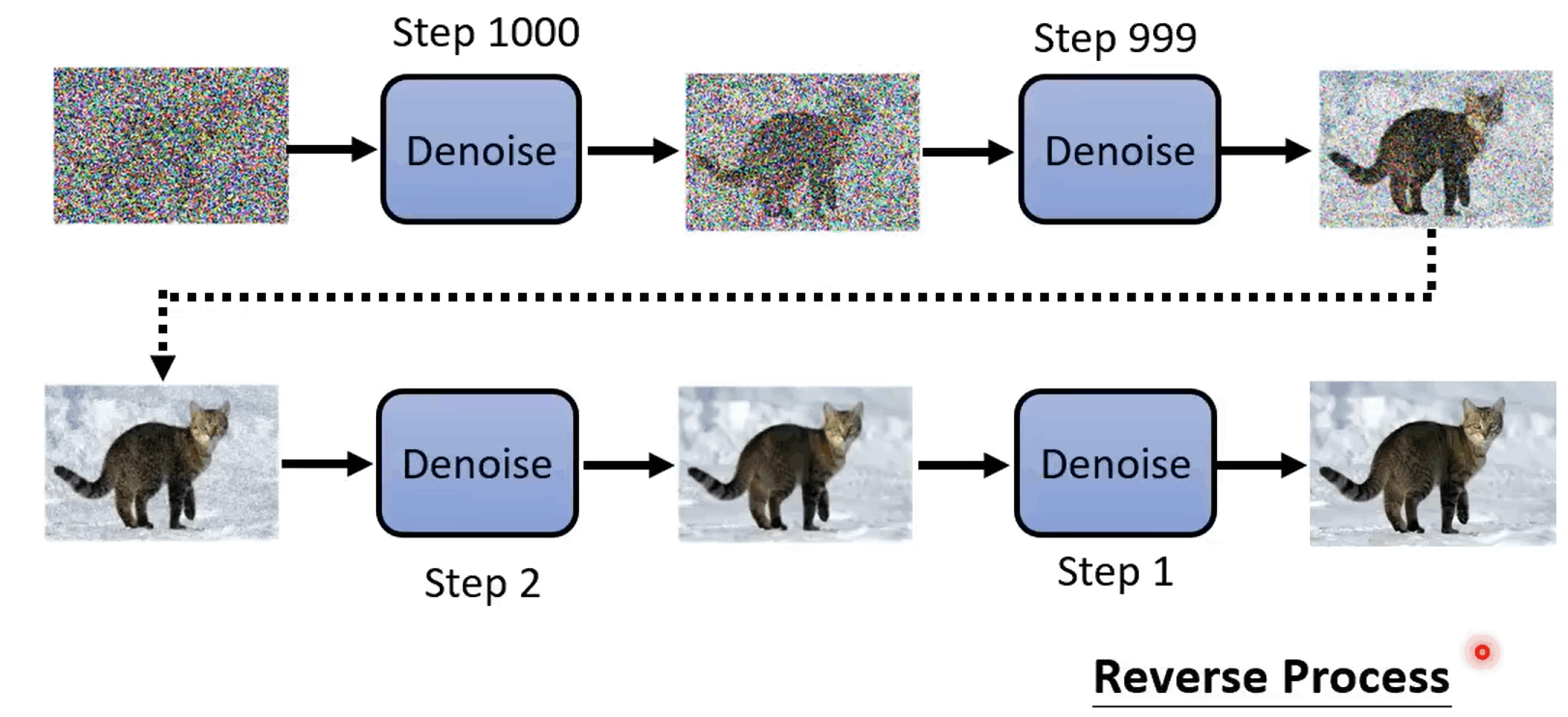
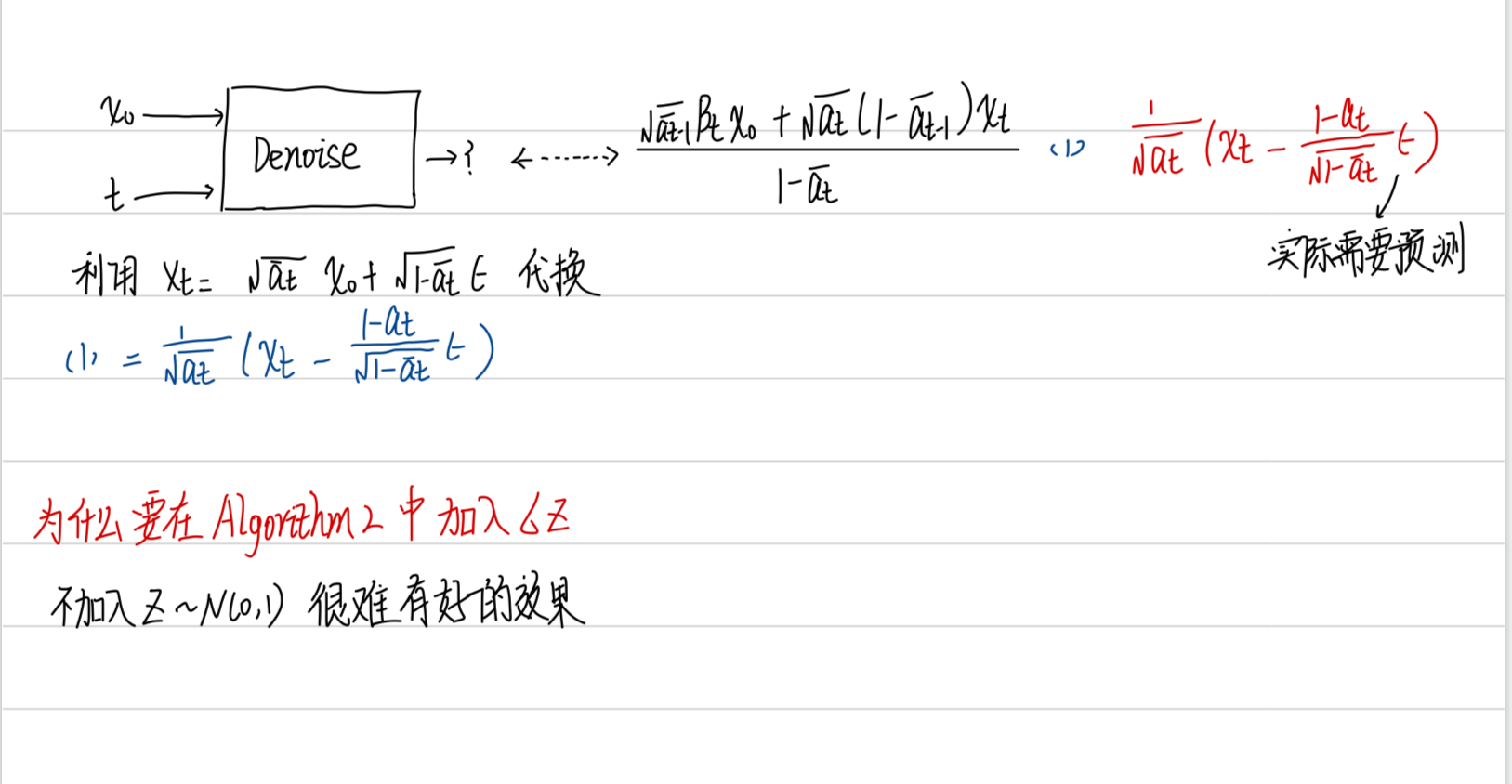
Denoise 是复用的,但是由于每次输入图象质量不一样,因此并不是真的只用一个 Denoise,而是既输入图像,也输入此时的步数 step
在 Denoise 网络中,主要完成:
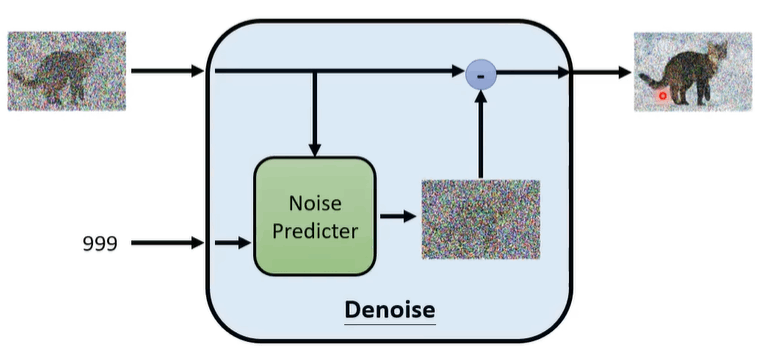
如何去训练 noise predictor?
训练的资料是人工创造出来的,从数据集中随机采集一张图像出来,然后随机采样一个高斯噪声,图像相加得到有噪声的图像。然后持续添加噪声,步数和去噪一样。这个加噪的过程称为前向过程(forward process / Diffusion Process)

此时步数相同的两个过程的图像,reverse process 中的是输入图像,forward process 中的是标签
Text-to-Image
像 stable diffusion 等模型,训练数据集来自于 LAION 数据集,总共有 5.85B 张图像,并且是文字-图像成对的资料
Denoise 模块的输入是 image,text,step
Stable Diffusion
框架组成:
Text Encoder:将文本转为向量
生成模型:将向量和噪声生成一个中间产物(图片的压缩版本,可以看懂也可以看不懂)
Decoder:将中间产物转为图像
三个部分分开训练,然后合起来再微调
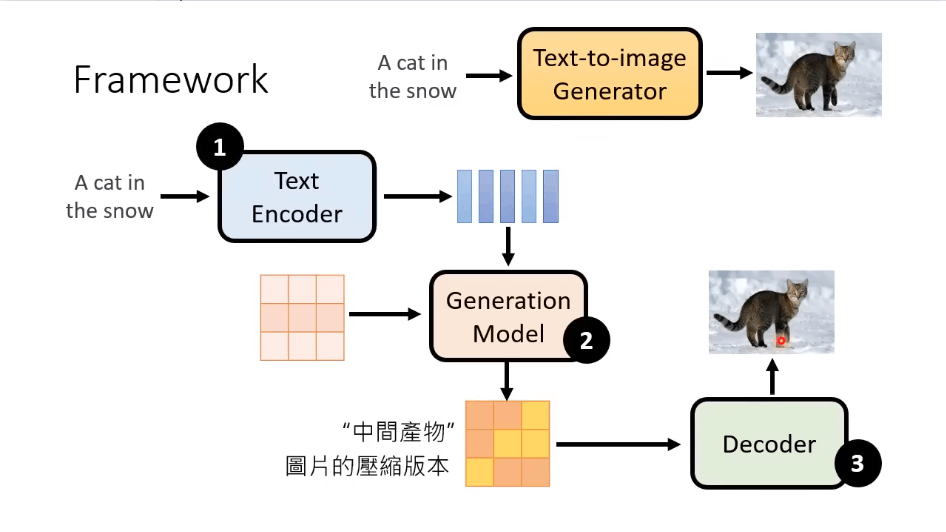
Stable Diffusion 结构
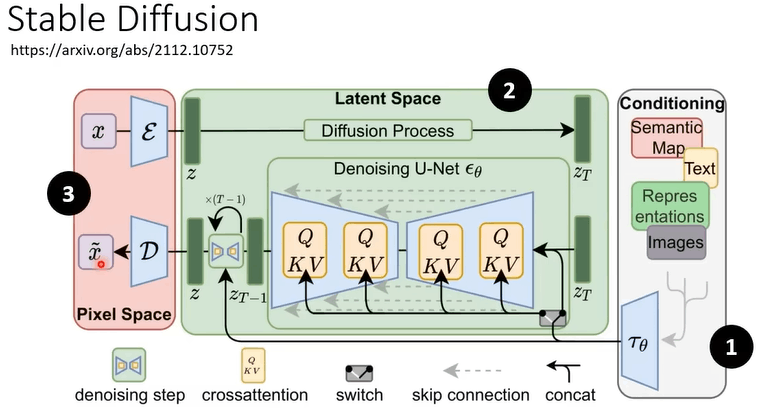
DALL-E 和 Imagen 都是类似结构
Encoder
衡量 Encoder 的好坏有两个指标:
Decoder
不需要文字和图像的 pair 的 data,不需要文字输入
如果中间产生的图像是小图,则训练 Decoder 只需要把图像及其缩小版作为训练数据集
如果中间产生的是 latent representation,则需要训练一个 Auto-Encoder,Encoder 将图像转为 Latent Representation,然后再通过 Decoder 还原为原图像,然后就将 Decoder 拿出来用
Generation Model
原理解析
![]http://cdn.zghhui.me/img//cdn.zghhui.me/img/Pasted image 20231227161621.png)