正在加载今日诗词....
📌 Powered by Obsidian Digital Garden and Vercel
载入天数...载入时分秒... 总访问量次 🎉
载入天数...载入时分秒... 总访问量次 🎉
Attention 首先出现于 2017 发表的《Attention Is All You Need》
Transformer 首先将句子划分为 tokens,每个 tokens 对应一个高维向量(Embedding),

在 Embedding 构成的向量空间中,方向也可以对应着语义.Transformer 的目标是逐渐调整这些 Embedding 使得它们不单单编码单个词,还能融入更加丰富的上下文信息。
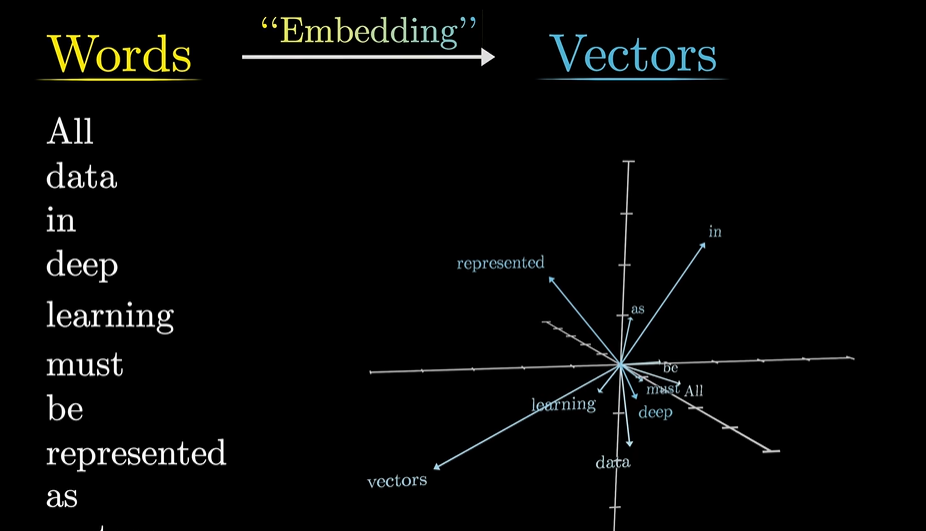
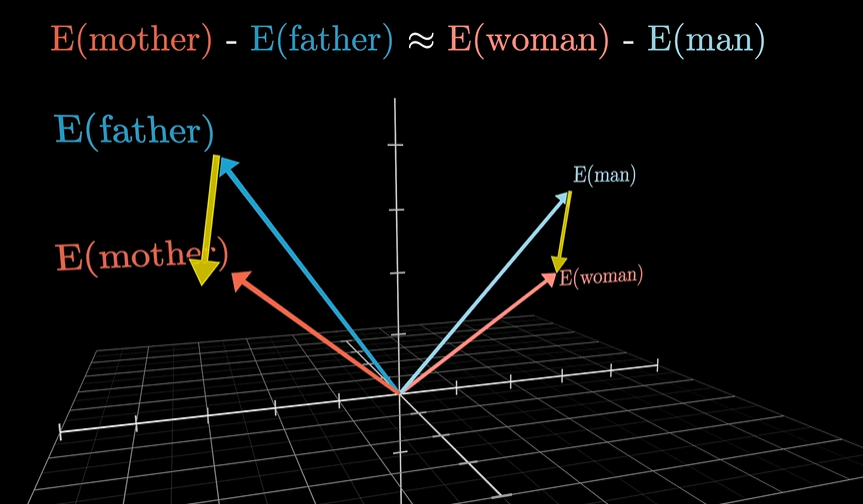
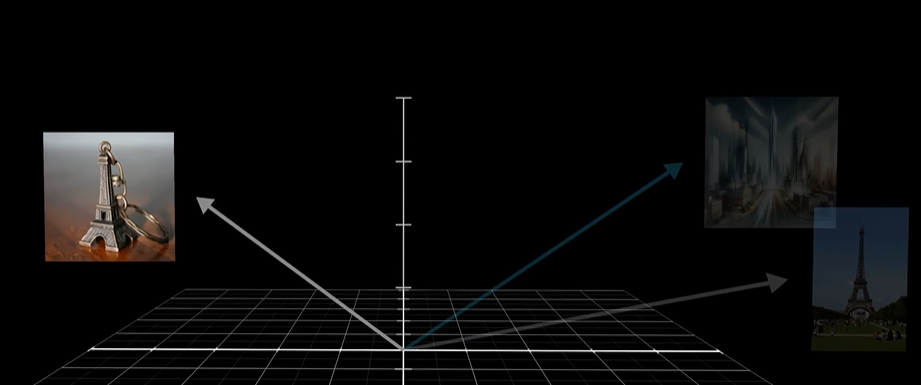
对于同一个词,在不同句子中可能会有着不同的语义,但在第一步的 embedding 中,得到的都是同一个 vector(先不考虑位置信息),初始的 embedding 是没有参考上下文信息的。可以这样想象,embedding space 中有多个方向,编码了这个单词的不同含义,训练好的 Attention block 能够根据上下文信息计算出给初始的 embedding 加上一个对应的向量,使得它移动到对应的向量上面
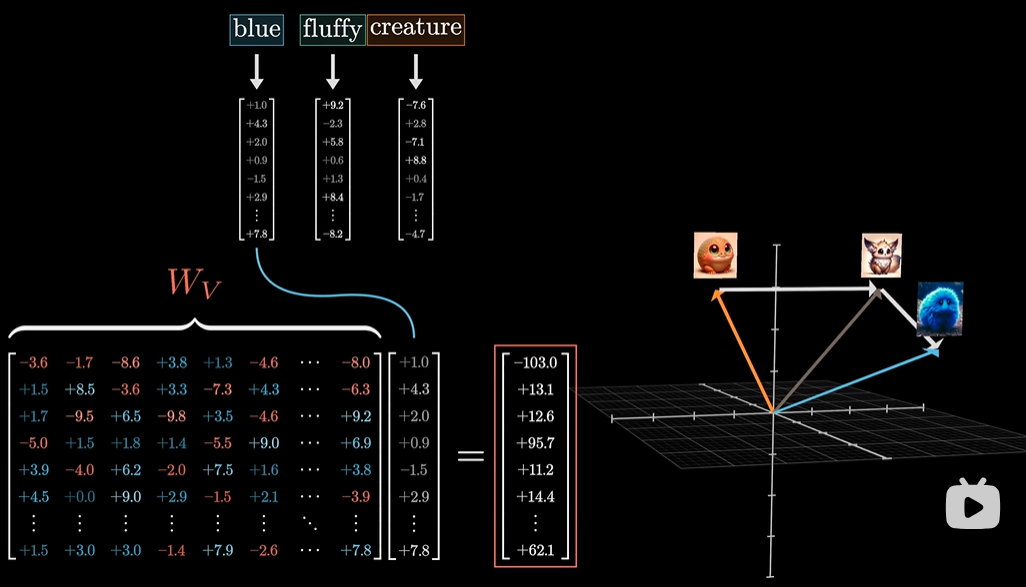
计算 attention 时,首先用
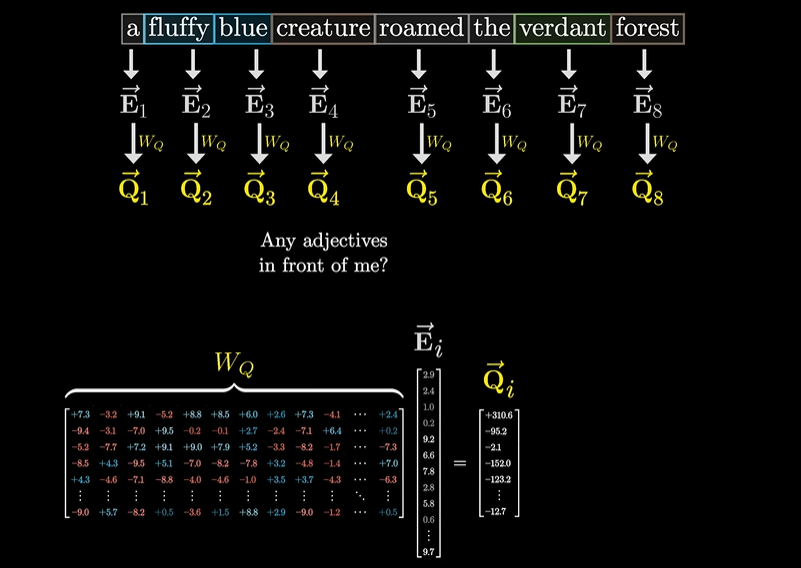
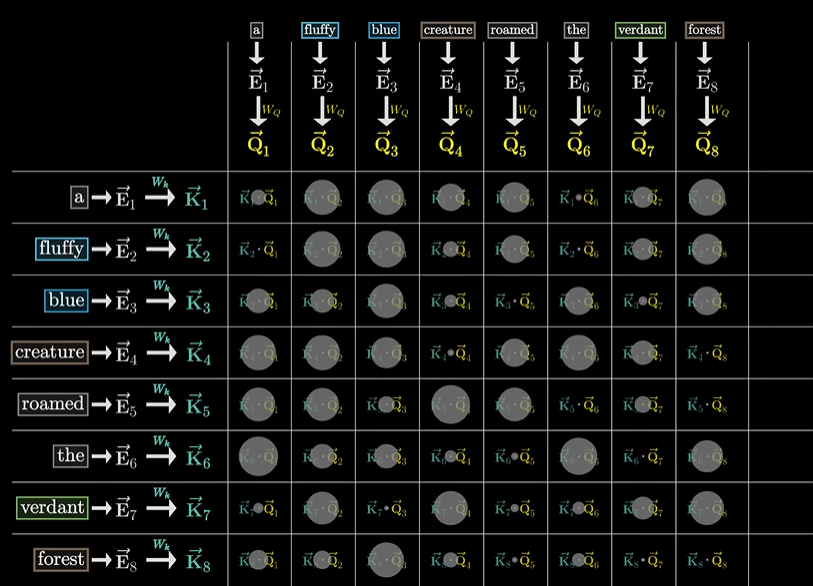
同时,也用相似的方法计算键
每一列表示该查询与所有键相对应的权重,因此需要满足总和是 1,所以需要使用 softmax 将这一列的值归一化,映射到 0-1 范围内。为了数值稳定性,需要将所有的点积除以查询-键的空间维度的平方根
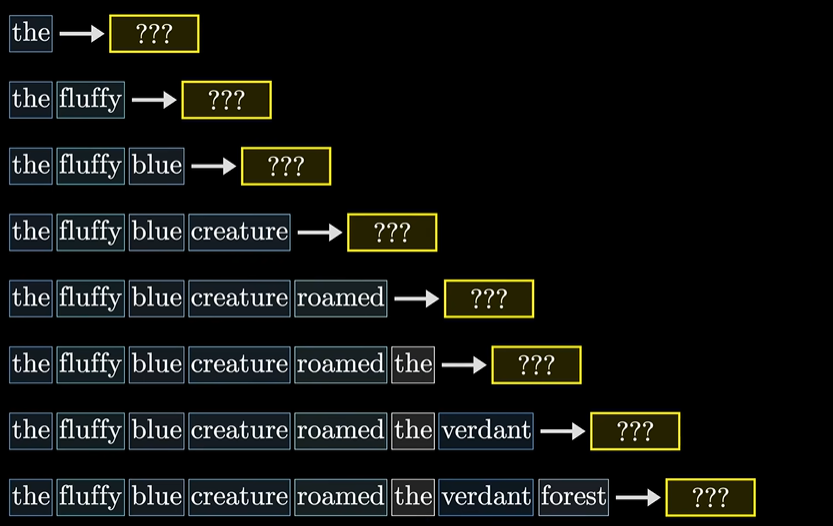
在训练模型过程中,一般而言是给定一段话,预测下一个词出现的概率,然后进行优化参数,一个效率比较高的方式是,对于每段话,让它同时预测每个子序列的下一个词出现的概率。
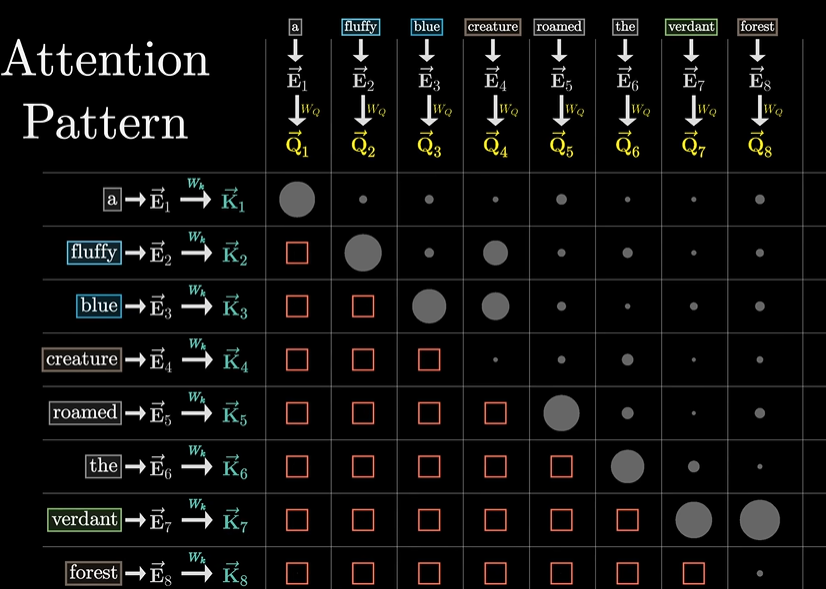
对于注意力而言,这就要求不可以让后面的词影响前面的词,因此需要对 Attention Pattern 中下三角区域的值进行置 0,常用的方法就是在经过 softmax 之前,将这一区域的值设置为负无穷-∞,经过 softmax 后,这部分区域的值就变为了 0,每一列仍保持归一化,这一过程称为掩码
如何得到 attention 计算的结果,此时还需要一个称为值