正在加载今日诗词....
📌 Powered by Obsidian Digital Garden and Vercel
载入天数...载入时分秒... 总访问量次 🎉
载入天数...载入时分秒... 总访问量次 🎉
不需要标注数据,从没有标注的数据中进行学习,将学到的东西(没什么用)用到下游的任务,其中 self-supervised learning 也可以称为 pre-train
在 Auto-encoder 中有两个 network
将一个高维度的输入转为较低维度的 vector(bottleneck)(dimension reduction),然后再进行处理
为什么需要 Auto-encoder
图像的变化是有限的,因此可以用较低的维度对图像进行表示
Auto-encoder 的想法在 2012 年 Hinton 的论文中已经有提及
De-noising Auto-encoder
在输入的图像中加入一些 noise,作为输入,经过 encoder 和 decoder 将图像还原为不加噪声的真实图像
其实在 BERT 中也用到这个思想(BERT 相当于是 Auto-encoder),被 mask 的地方就是加入的 noise,BERT=》Encoder,得到 embedding,经过的 Linear 相当于 Decoder,输入就是去掉 mask
解耦:把原本纠缠在一起的东西解开
将内容输入到 Encoder 中后,会得到包含输入信息的 vector,如输入的是图像,vector 可能包含纹理;输入是声音包含内容和说话人;输入的是文本则可能包括语法……但信息中的内容到底在 vector 中的哪些维度代表哪些内容很难知道
特征解耦就是使 vector 中的信息能够有规律可循,能够将输入中的信息分到相应的部分(上中下)
应用:
voice conversion
分别 train 两个 encoder-decoder,经过 feature disentanglement 后,可以得到 vector 中不同的维度分别代表什么信息,然后将两个 vector 中表示说话人的部分进行互换,从而得到声音的互换
Discrete Latent Representation :离散潜在表示
在一开始的假设中,中间的 vector 使一些数字(real number),但也可以用 binary,其中每一位表示是否有某个特征,或者也可以用 one-hot 表示
Vector Quantized Variational Auto-encoder(VQVAE)
将 encoder 的输出与一排向量(CodeBook)进行计算相似度,选择相似度最大的 vector 拿出来作为 decoder 的输入(encoder decoder codebook)是要学习的内容
embedding 可以是向量也可以是一段文字,此时 encoder 和 decoder 需要是 seq2seq 的模型。此时的模型是 seq2seq2seq auto-encoder,此时可以希望中间的内容可以是摘要,这样就实现了 unsupervised learning 的自动生成摘要的任务,但实际上中间生成的是 encoder 和 decoder 的‘‘暗号’’,只有他们自己可以看懂。因此,可以加入一个 discriminator,他判断这段文字是否是摘要,此时 encoder 将要生成一段可以让 decoder 复原回原本内容的 embedding,通过也要骗过 discriminator,让他认为这是一段摘要。(等价于 cycle gan)
将 auto-encoder 中的 decoder 拿出来,可以作为一个 generator,除了 GAN 可以作为 generator 模型,还有 VAE(variation auto-encoder)也可以
可以将 encoder 的输出作为压缩的结果
encoder 是压缩,decoder 是解压缩
给定训练数据,检测输入 x 是否是训练数据的资料
诈骗检测,网络检测,癌症检测
一般异常检测不是二分类的问题,而正样本远大于负样本。一般可以这样做:
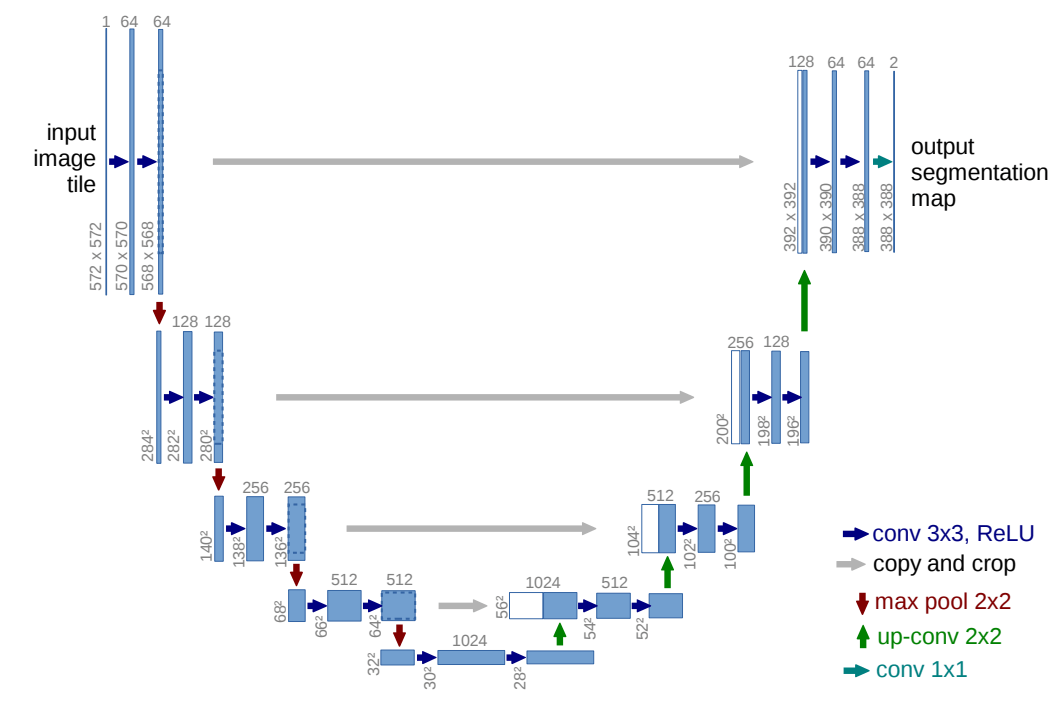
输入图像的尺寸为:1x572x572,输出图像为:2x388x388
中间灰色线为:裁剪和拼接
上采样可以采用两种方式实现:
Conv2d(1, 64, 3, 0, 1), Conv2d(64, 64, 3, 0, 1), Maxpool(64, 128, 2)
KL 散度:
KL 散度(Kullback-Leibler Divergence)是用来度量两个概率分布相似度的指标
P Q 是两个分布,若是离散分布
若是连续分布
对于 auto-encoder 来说,每一种输入对应一种 vector,每种 vector 对应一种输出,而 VAE 则是在 vector 中加入一些 noise,使得一些 vector (在原本 vector 附近)都可以产生一种输出,因此可以产生介于一种输入和另一种输入之间的新输出
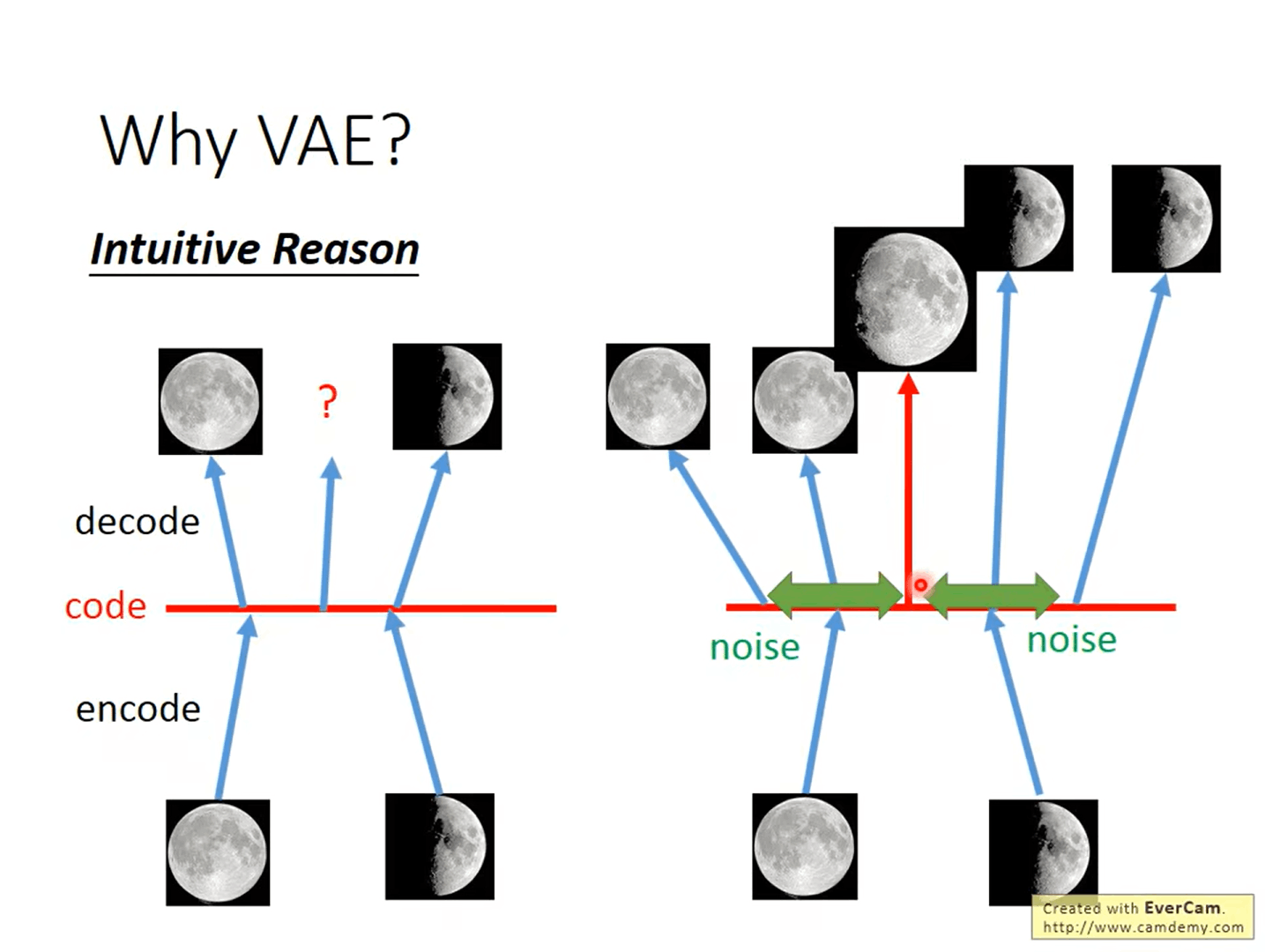
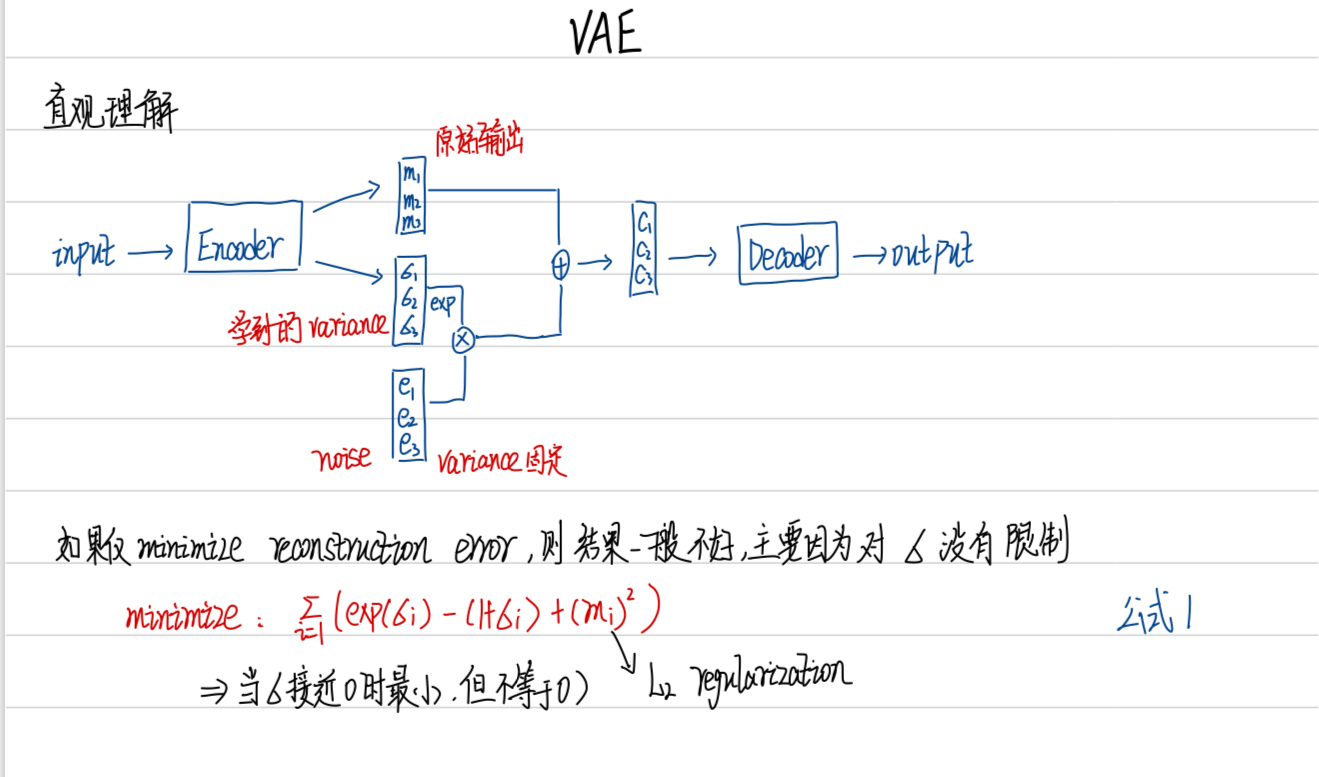
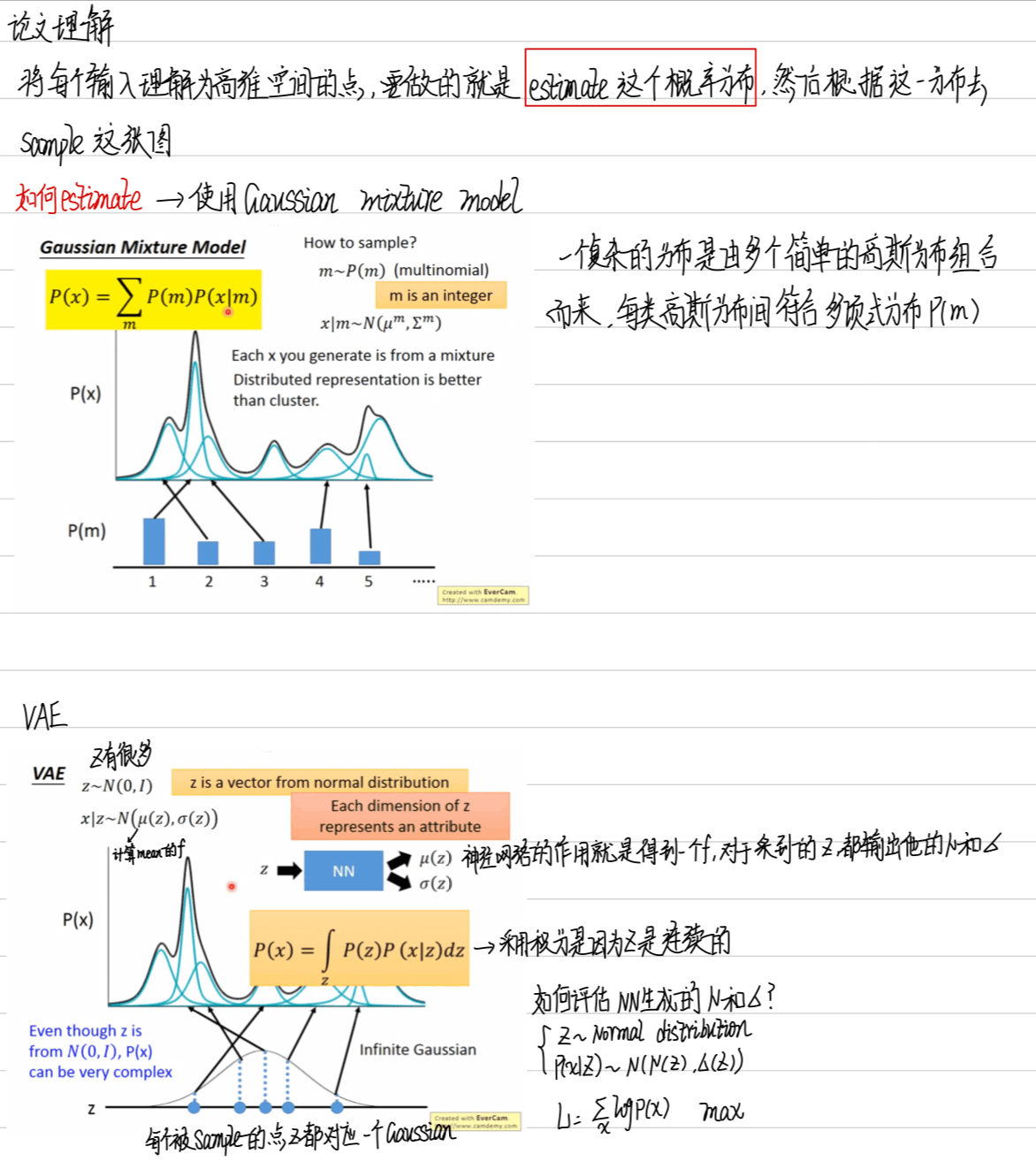

现在 VAE 可以产生一个数字,Conditional VAE 看到一个数字可以把数字的特性抽出来,在输入 Encoder 时,一方面输入有关数字的特性,还有输入的什么数字,可以输出跟这个数字风格很相近的数字
没有真正的学如何去产生一个数字,只是让输出和真实的很接近,往往产生的是已经存在的 image,而不是生成新图像(模仿)