正在加载今日诗词....
📌 Powered by Obsidian Digital Garden and Vercel
载入天数...载入时分秒... 总访问量次 🎉
载入天数...载入时分秒... 总访问量次 🎉
Authors:
Daeun Lee,Jaehong Yoon,Jaemin Cho,Mohit Bansal
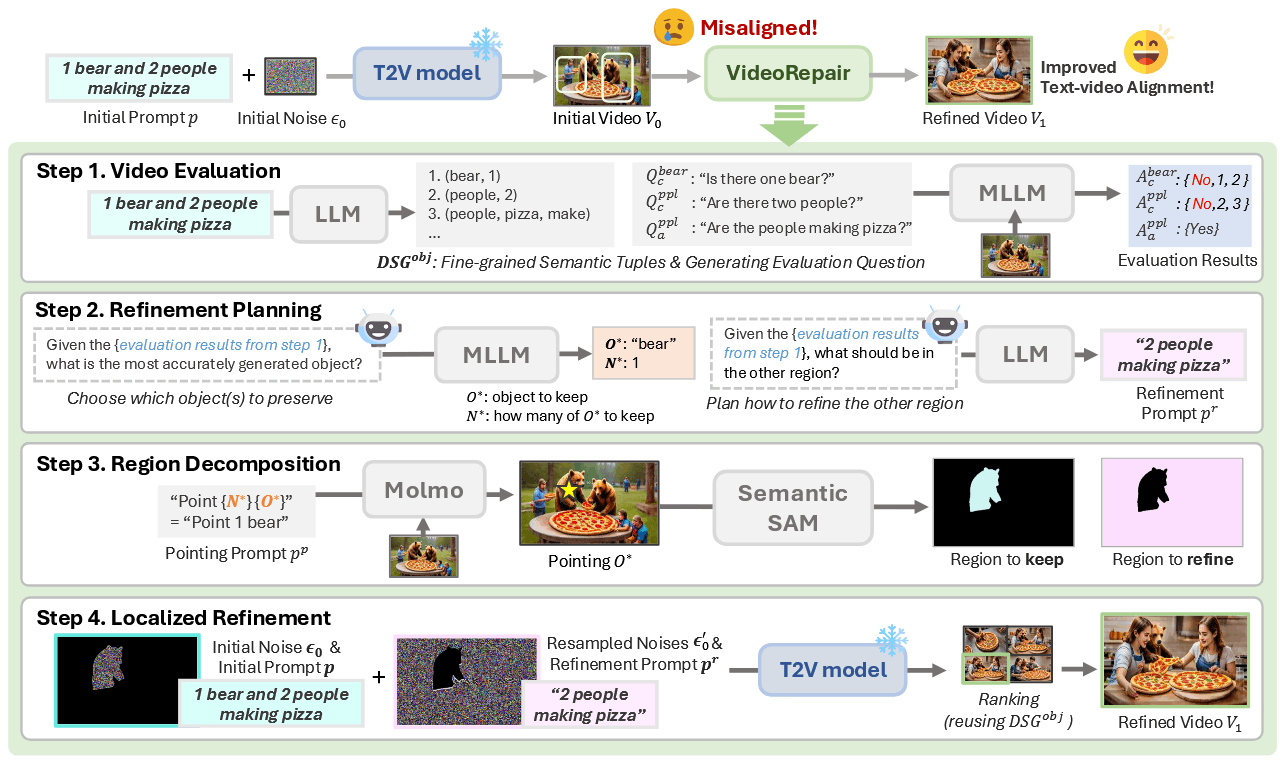
T2V 模型已经能够生成高质量和多样性的视频,但这些模型经常出现视频和文本不对齐的现象。本文提出了 VIDEOREPAIR 的改进视频-文本不对齐的框架。具体来说包括一下四步:
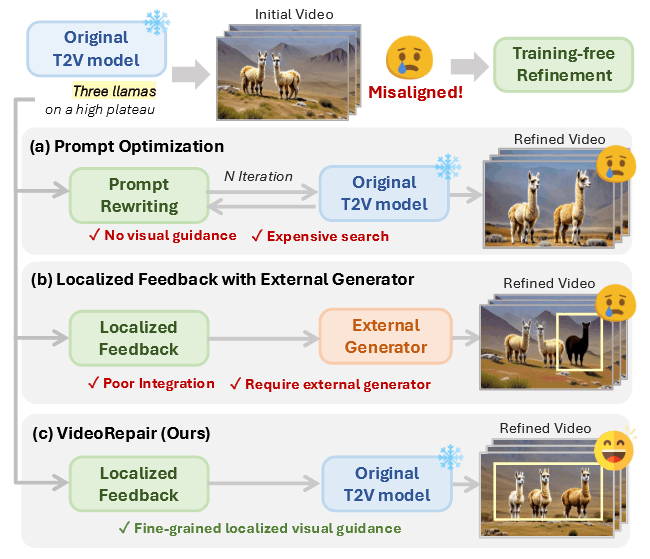
现在一些有一些 training-free 的工作来增强文本和视频的对齐。Prompt optimization 通过 LLM迭代的搜索更好的 prompt 并选择得分最高的视频,但这种方法没有显示的反馈,并对噪声十分敏感,需要多次迭代才能够实现很好的对齐。SLD 提出了利用显示指导的细化框架,具体来说是指用一个 LLM 来生成 bounding box 级别的规划,然后运行物体增加、删除和复位等操作,但是物体添加需要额外的布局指导生成器,导致不和谐场景的出现。
首先通过评估问题列表来判断生成的视频中 prompt 中哪些元素没有对应上,具体来说通过 LLM 提供手动编写的上下文示例来生成以对象为中心的问题。与 DSG 相似,首先定义包含实体、属性以及关系的语义类别。用一个语义组
然后通过回答来确定视频中的不对齐错误。分别为属性元组和关系元组生成对应的问题
在得到属性和数量关系的结果后,下面确定的是哪些视觉内容需要被保留,通过
细化区域的prompt 重新生成。在生成过程中,应当对不同的区域进行分别的控制,因此对于需要细化的区域,应该重新生成一个 refined prompt
SLD 使用开放词汇检测器基于 bounding box 来检测局部错误,T2V 相较于 T2I 而言,场景会比较复杂,经常出现属性混合的复杂情况,此外使用 bounding box 分割每个对象会使得交互变得复杂。
为了确定保留区域,论文使用 Molmo 来的获得一个对象的 2d 坐标点,然后使用 Semantic-SAM 坐标点指导来得到一个更为准确的局部 mask
局部噪声重新初始化。在重新生成视频时,保留 mask 内部的噪声,重新初始化外部噪声。为了得到 latent mask,主要是对 pixel mask 通过池化的方法进行放缩。新的噪声通过下面的方式得到。
同时,对于保留区域使用原始的 prompt 进行控制,未保留区域通过 refine 后的 prompt 进行控制。