正在加载今日诗词....
📌 Powered by Obsidian Digital Garden and Vercel
载入天数...载入时分秒... 总访问量次 🎉
载入天数...载入时分秒... 总访问量次 🎉
Authors:
Fuying Wang,Yuyin Zhou,Shujun Wang,Varut Vardhanabhuti,Lequan Yu
随着大规模标记数据的增长,深度学习技术促进了医学图像理解的进步,然而这类标记数据是十分昂贵的,并且很耗费时间。因此,直接从医学图像中直接学习逐渐变成了主流,即致力于从医生详细的医学报告中学习通用的诗句表征,并将其应用于下游的计算机视觉任务。
先前的工作关注于病理学往往只发生在整个图像的局部很小的位置,因此基于 attention-based 的对比学习策略被提出来学习局部表征。
医学图像和医学报告展示出了多粒度的语义关系,如 disease-level, instance-level, and pathological regionlevel。现有的方法并没有将这些维度全部考虑在内,没有充分利用报告中的信息,进而导致了不充分的模型表征能力。
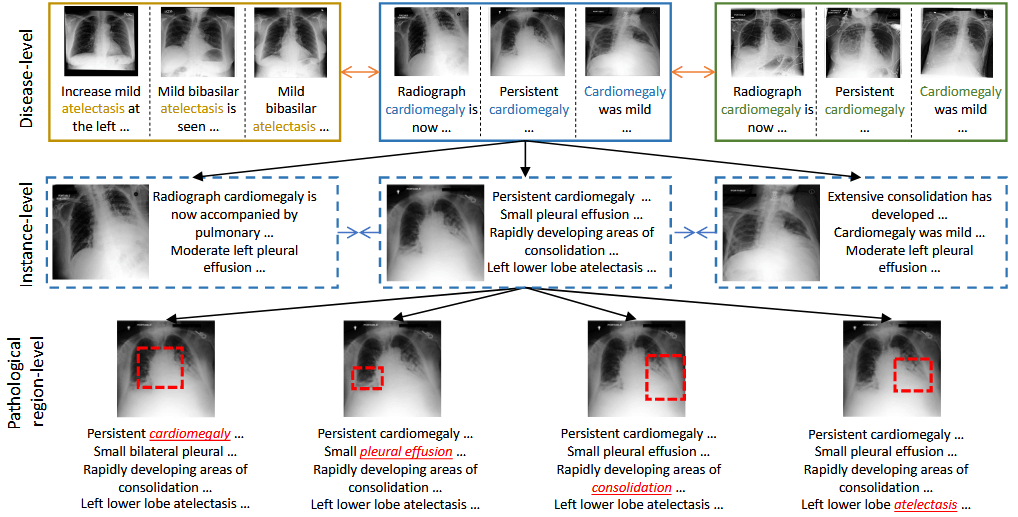
本文提出了 MGCA(Multi-Granularity Cross-modal Alignment)来充分利用这种报告和图像的多粒度关系,通过三种对齐:instance-wise alignment,token-wise alignment 和 disease-level alignment 来提升视觉表征的泛化性。
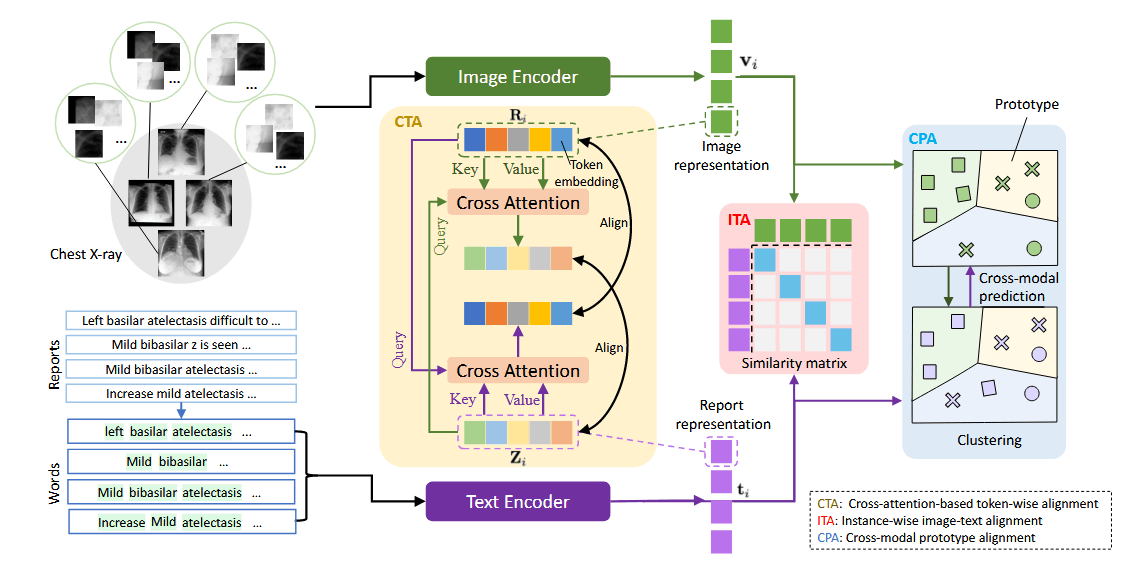
报告和图像首先通过 Text Encoder(BERT)和 Image Encoder(ViT)编码为 Image Representation(绿色) 和 Report Representation(紫色).
Instance-wise Image-Text Alignment(ITA): 整个框架的核心主力,用于报告-图像对映射到相近的空间,而不成对的映射到较远的距离。首先使用非线性映射层将文本和图像embeding 映射到标准化的低维空间,然后计算每对的余弦相似度。然后使用对称的标准化 InfoNCE losses 来最大限度地保留潜在空间中真实对之间的互信息。这部分可以表示为:
这部分的 loss 为:
Cross-attention-based Token-wise Alignment(CTA): 病理只占整个图像的一小部分,报告中只有少数疾病标签描述了关键的医疗状况,基于这个情况,本文提出使用基于双向交叉注意力的 Token-wise 对齐。首先将将文本和图像 embeding 映射到标准化的低维空间,然后通过 cross attention 来计算视觉和文本 tokens 的软匹配,即让视觉 tokens 去关注所有的文本 tokens,然后计算它对应跨模态文本 embedding
然后让文本 tokens 尽可能接近他对应的 cross-modal 文本 embedding,然后远离其他的。考虑到不同的视觉 tokens 有不同的作用,因此为每个视觉 tokens 都设置了一个权重,文本部分相应的 loss 可以写为:
视觉部分也进行类似的计算,这部分总体损失为文本和视觉部分的 loss 的均值。
Crossmodal Prototype Alignment(CPA): ITA and CTA 将不同的实例都作为了负样本对,忽视了不同病理之间存在着相似的高级语义信息。对于疾病级别的对齐,本文通过强制执行跨模式聚类分配一致性来利用医学图像和放射学报告之间的受试者间关系对应关系。具体来说,Sinkhorn-Knopp聚类算法通过将文本和视觉分为 K 类,得到两个软簇分配代码,然后分别计算文本和诗句部分的 CE Loss
最后,总的 loss 为三部分 loss 和: